
点击链接去看看 --> https://cstweb.top/py-data-work/python_bili_video_data_analysis.html
爬虫实战-随机爬取B站2021年视频信息
这学期通过学习python数据分析,写了个爬虫Python脚本,刚好作为这门课期末作业交了,我爬取的是B站2021年视频信息数据。
备注:爬取的数据仅为了学习爬虫技术,无盈利无传播
使用技术
开发环境:python3 + Pycharm
数据分析库包
- python网络爬虫:requests 、pymysql、requests、pyquery
- 数据分析与存储:MySQL、NumPy、Pandas、re
- 数据可视化:Quick BI
爬虫思路
-
先去B站寻找所需的视频,F12打开调试,找到相应的数据接口或页面,分析其接口的参数信息,以下三接口是本项目的爬取核心接口
-
# 爬取B站视频信息(含播放量、点赞数等)的接口 bili_video_info_URL = "https://api.bilibili.com/x/web-interface/archive/stat?aid={}" # 爬取B站视频的类别标签的接口 bili_video_tag_URL = "https://api.bilibili.com/x/web-interface/view/detail/tag?aid={}" # 爬取B站视频的HTML 文本信息,用于获取视频标题和视频发表时间 bili_video_name_URL = "https://www.bilibili.com/video/{}"例如下方是 爬取B站视频信息(含播放量、点赞数等)的接口,返回的JSON数据 { "code": 0, "message": "0", "ttl": 1, "data": { "aid": 2, "bvid": "BV1xx411c7mD", "view": 3394733, "danmaku": 103196, "reply": 75021, "favorite": 84651, "coin": 29730, "share": 13916, "like": 185117, "now_rank": 0, "his_rank": 0, "no_reprint": 0, "copyright": 2, "argue_msg": "", "evaluation": "" } } 当前节点:JSON.data -
如果碰到接口返回的不是JSON数据,而是直接渲染在页面上,此时需要将爬取网页的HTML文本,通过pyquery的JQuery语法提取页面标签中的内容
text = requests.get(bili_video_name_URL.format(data["bvid"]), headers=headers).text q = pyquery.PyQuery(text) q("h1[title]").text(), # HTML中提取 视频标题 q("span:eq(11)").text() # HTML中提取 视频发布时间 -
通过分析,调取这些接口时,发起Get请求时,需要传入bvid或aid的参数,这也就是B站存视频的ID号,且我发现这些ID都是有规律的,视频ID号都是递增的方式,这里我猜测B站存视频信息的ID号是使用数据库中常见的主键ID自增长的形式,所有我用多个不同范围内的数字去尝试,得出了个结果:B站2021年的视频的ID号 范围在(203432111 ~~ 219813111 之间),所以爬取2021年的视频数据,传给对应参数的aid只要在这范围内,就能爬取到数据,如果爬到的是空数据,则跳过当条,期间还解决了一些aid转bvid的事项,爬数据时传入的aid我使用 python的随机数,确定好随机数的范围就行。
"https://api.bilibili.com/x/web-interface/archive/stat?aid={}" .format(random.randint(203432111, 219813111) -
数据存储,爬下来的数据我存在MySQL数据库
def save_db(): # 将爬取的数据保存至服务器上的数据库 global result, cur, conn, total sql = "replace into bili_video values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s,now()) ;" try: cur.executemany(sql, result) except Exception as e: print("数据回滚:{}", e) conn.rollback() conn.commit() print("本次数据保存成功,当前进度 {}/10000 ---- {} %".format(total, total / hopeTotal * 100)) result.clear() #创建数据表 cur.execute( """create table if not exists bili_video (v_aid int primary key, v_bvid varchar(50), v_view int, v_danmaku int, v_reply int, v_favorite int, v_coin int, v_share int, v_like int, v_name text, v_tags text, v_pubtime datetime, create_time datetime) """ ) #为了提升效率,我们插入数据到数据库时,可以使用批量插入,不要每爬一次,就插入一次数据,这样效率不高哦 total += 1 # 每爬取200条数据,批量保存一次到数据库 if total % 200 == 0: save_db() result.clear()注意点:SQL语句我使用replace而不是insert,因为在爬取的过程中,因为是随机的,所以在爬取过程中是有可能碰到重复的,所以使用replace,当碰到重复的数据,替换它即可,避免了没必要的异常出现。
-
数据爬取方式和遇到的问题爬取数据
爬取数据的核心代码
time.sleep(1) # 每次请求,间隔1秒,避免太快 IP被封 req = requests.get(url, headers=headers, timeout=10).json() data = req["data"] if data["view"] != "--" and data["aid"] != 0: req_tag = requests.get(bili_video_tag_URL.format(data["aid"]), headers=headers, timeout=10).json() tag_list = req_tag["data"] tags = ",".join([tag["tag_name"] for tag in tag_list]) text = requests.get(bili_video_name_URL.format(data["bvid"]), headers=headers).text q = pyquery.PyQuery(text) video = ( data["aid"], # 视频编号 data["bvid"], # 视频bvid编号 data["view"], # 播放量 data["danmaku"], # 弹幕数 data["reply"], # 评论数 data["favorite"], # 收藏数 data["coin"], # 硬币数 data["share"], # 分享数 data["like"], # 点赞数 q("h1[title]").text(), # 视频标题 tags, # 视频的分类标签 q("span:eq(11)").text() # 视频发布时间 ) print("正在爬取,{}".format(video))怎么保证高效的爬取?如果只在本地爬取,那么电脑要一直开着,不方便,所以我把这python脚本放在了个人的云服务器上跑,配置好爬虫所需的环境后,最好将print语句换成logger日志输出方式方便实时查看,然后即可24小时不间断的进行爬取。
不过也遇到了问题,当爬取速度过快时,会存在IP被限制、被封的情况,这种时候就无法继续爬取了,往往要等一段时间才能解封。我的解决方式是;每爬取一条数据时,程序睡眠1秒再进行,这样有效解决了IP被封的情况,但有时爬的速度慢B站也可能会封禁,这时候我在程序中通过得到接口返回的状态码,判断状态码的参数,即可得知IP是否被限制,如果被限制了,则让程序休眠十分钟,再继续尝试,使用这样的解决方式后,爬虫的效率显著提高了。req = requests.get(url, headers=headers, timeout=10).json() data = req["data"] if req["code"] == -412: print("IP被封了, 休眠10分钟后继续尝试...") time.sleep(600) pass -
数据清洗分析和可视化
Python爬虫是语言优势,工具封装生态完善、效率高 使用NumPy、Pandas、阿里的Quick BI 可视化工具,分析数据库中的,过滤和筛选所需的数据,配置对应的类别轴/维度、值轴/度量、进度指示/度量、扇区标签/维度等参数,生成相应的图表。 ----源码后续整理好可能会开源Quick-BI
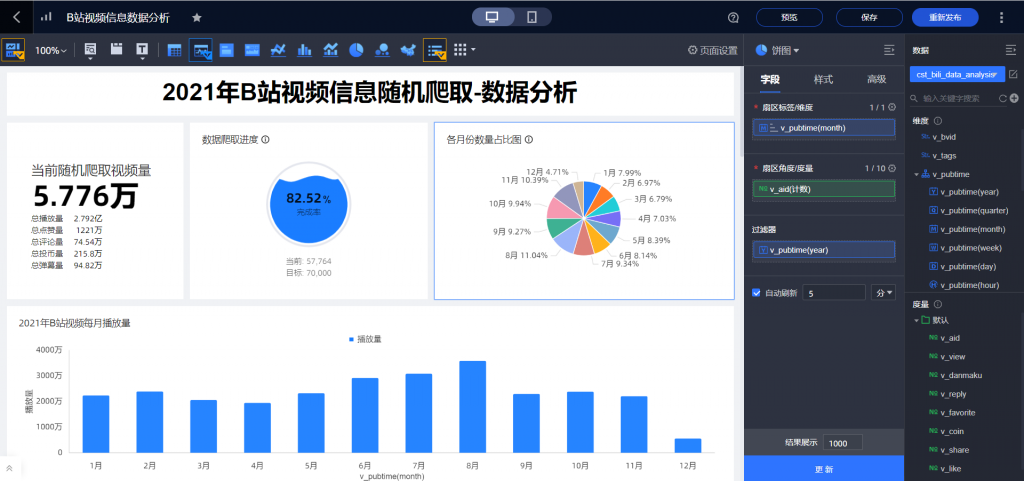
总览图
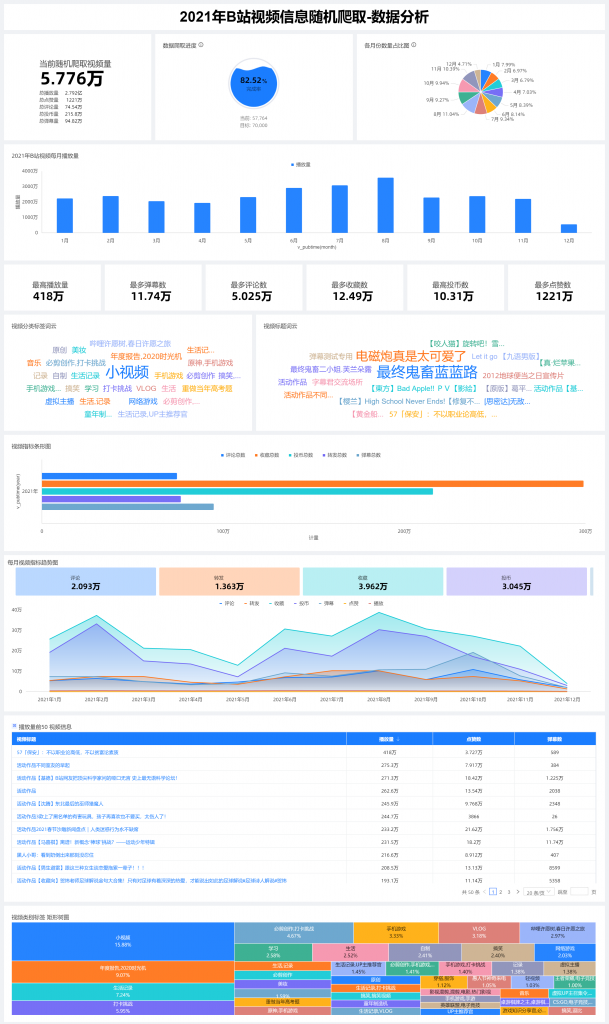
本次
tadalafil 10mg without prescription – tadalafil 5mg canada cialis super active
cost of ivermectin cream – stromectol brand ivermectin 9mg
buy viagra 50mg without prescription – viagra price buy ranitidine 300mg generic
rx pharmacy online cialis – cialis 10mg sale ivermectin lotion for scabies
viagra on line
viagra plus
where can i get viagra for women
ivermectin cost
over the counter viagra 2017
ivermectin 50mg/ml
buy viagra australia online
viagra order online
cipro antibiotics
atarax online pharmacy
cost of diflucan in india
kamagra oral jelly distributor
tetracycline 1000
chloroquine purchase online
order zithromax online canada
mebendazole price
zoloft 25 mg pill
fluoxetine discount
vpxl pills
tadacip 20 mg uk
amoxicillin 650 mg price
tretinoin cream purchase online
zestoretic online
suhagra 100mg price canadian pharmacy
purchase amoxil without prescription – amoxicillin 250mg ca viagra 50mg pills for men
viagra pills
viagra for sale
viagra
buy viagra online
buy viagra online
tadalafil 20 mg medication
cialis 20mg over the counter – cialis 20mg without prescription buy cialis 20mg pills
get viagra
sildenafil cost compare
buy generic viagra online usa
viagra for women buy
cost of sildenafil in canada
erectile dysfunction viagra
stromectol for sale online – ivermectin 6mg oral azithromycin 500mg price
generic viagra soft
generic cialis daily
viagra 100mg tablet buy online
generic cialis online canada
cheap cialis usa
cialis 40 mg for sale
online order viagra in india
viagra 100mg tablet price in india online
viagra pills price in south africa
cheap generic viagra 50mg
order cialis canadian pharmacy
cialis soft 20 mg
cialis online pharmacy india
viagra best buy india
cheap zithromax – buy lasix 100mg without prescription medrol 16mg oral
brand viagra 100mg price
cheapest viagra prices
purchase cialis from canada
buy cialis tablets
20 mg sildenafil 30 tablets cost
how to buy viagra from india
avodart cost canada
ivermectin oral
order baricitinib 2mg generic – order chloroquine 250mg online purchase priligy sale
clomid price canada
bactrim in mexico
robaxin 750
buy cheap sildalis fast shipping
buy generic albuterol
generic for levaquin
how to get nolvadex prescription
order glucophage generic – canadian pharmacy meds buy generic lipitor 10mg
synthroid 15 mcg
ampicillin iv
hydroxychloroquine 900 mg
tenormin buy
allopurinol online canada
singulair medication cost
phenergan 12.5 mg tablets
order norvasc 10mg generic – order prilosec 20mg pill buy omeprazole generic
zofran online uk
cheap zofran australia
buy avodart singapore
where to get amoxicillin over the counter
metformin from mexico
price of inderal 10mg
inderal order online uk
order metoprolol 100mg without prescription – buy lopressor 50mg pills order tadalafil 40mg without prescription
anafranil 50 mg capsule
buy cialis online fast shipping
cost of valtrex in india
buy advair on line
buying bactrim online
combivent medication
india tadalafil
where to buy tadalafil
cialis 10mg oral – cialis 20mg tablet sildenafil mail order us
buy viagra japan
ivermectin 3mg tab
purchase cialis with paypal
online viagra cheap
where to buy viagra online without prescription
ivermectin online pharmacy – ivermectin 12mg for humans for sale ivermectin 0.5%
buy cialis price
viagra soft generic
how to get cialis coupon
canadian rx viagra
cialis for daily use generic
where to buy viagra online without prescription
cialis cost
avodart canada pharmacy
cost of singulair in canada
order finasteride
viagr
strattera 20mg price
modafinil uk paypal
dipyridamole 75 mg tab
order clomiphene without prescription – clomid generic cetirizine 10mg oral
female viagra sale in singapore
can i buy viagra in uk
buy cialis paypal
tadalafil 20mg cheap online
buy viagra 100mg online uk
viagra shop
buy generic viagra
buy desloratadine 5mg generic – purchase loratadine for sale aristocort 10mg pills
viagra without a prescription
how to buy female viagra in india
cheap 10 mg tadalafil
buy viagra paypal online
can you buy sildenafil
cilias canada
purchase misoprostol pill – order cytotec 200mcg sale synthroid over the counter
misoprostol where to buy
clindamycin 150mg capsules
ivermectin drops stromectol ingredient ivermectin for human
retin a cream discount
benicar 40 mg
cephalexin 600 mg tablets
vermox otc
ivermectin 8000
purchase viagra online in usa
stromectol uk
price of inderal 10mg
sildenafil 50mg uk – viagra overnight shipping usa buy gabapentin pill
cialis without a prescription
prescription medication atarax
generic viagra soft gel capsule
buy atarax
buy discount viagra
how to order cipro
canadian drugstore viagra online
zyban for depression
generic lipitor for sale
viagra brand online
order tadalafil 20mg generic – cenforce 100mg drug cenforce 50mg usa
doxycycline tablets over the counter buy doxycycline medicine doxycycline 50 mg cap
compare generic viagra prices
generic viagra sales
diltiazem buy online – buy zovirax 800mg for sale buy zovirax 800mg for sale
viagra online purchase india
buy viagra without presc
viagra for sale online australia
sildenafil for sale
cialis viagra australia does female viagra work picture of generic viagra
zestril 10 mg price in india
stromectol cost
hydroxyzine online buy – hydroxyzine 25mg us order generic crestor
buy metformin 850 mg
buspar pill 15 mg
how much is amoxicillin online
where to buy cheap viagra in usa
straterra order
cymbalta rx
stromectol 3mg cost
ivermectin 0.5 lotion
clomid online pharmacy clomid online cheap clomid buy online cheap uk
stromectol price usa
order zetia sale – domperidone 10mg oral order citalopram
10mg cialis for daily use
buy viagra brand
where can i buy viagra online viagra on line purchase nitric oxide and viagra
buy generic viagra – lisinopril online buy flexeril price
cialis online buy
buspar medicine
cheap prices for cialis
cost of prednisone 5mg tablets
ivermectin 2ml
cheap cialis prices
ivermectin antiviral
buy sildenafil sale – sildenafil canada buy tadalafil 40mg online
where can i get clomid uk where can i buy clomid pills where can i buy clomid medicine
zofran 8 mg price
cheap 5mg tadalafil
where can i buy viagra tablets
cheapest viagra prices
buy viagra online fast shipping
order toradol online – buy baclofen 10mg generic baclofen 25mg canada
tadalafil purchase online
cheapest genuine cialis online
viagra cream in india
sildenafil chewable tablets
vigra
brand colchicine 0.5mg – buy inderal 20mg for sale generic strattera
vermox canada pharmacy
lopressor 12.5 mg tablets
online xenical
800mg tetracycline
order generic viagra uk
tadalafil 20 mg for sale online
online viagra india
viagra triangle
cheapest online sildenafil
tadalafil best online pharmacy
purchase sildenafil generic – order sildenafil 50mg order viagra 150mg without prescription
nexium 40mg uk – promethazine online order order phenergan pill
buy cialis 40mg pill – Cialis no rx cheap cialis 20mg
order generic provigil 100mg – order modafinil 100mg pill medicine for impotence
cialis purchase cialis overnight cialis coupons
isotretinoin usa – order zithromax pills zithromax 500mg pill
lasix 40mg ca – buy viagra 150mg without prescription buy viagra 150mg online
cialis and viagra mix where to buy cialis cheap cialis over the counter
tadalafil tablets – buy cialis 40mg pills buy sildenafil 100mg pill
ivermectin for dogs side effects stromectol france ivermectin cream before and after
buy topamax sale – imitrex 25mg usa order sumatriptan generic
cialis pills for sale how to take cialis 5mg what does cialis cost
avodart uk – order cialis online cheap order cialis 10mg pills
viagra 150mg tablet – cheap viagra generic cialis tablets
generic cialis us pharmacy does cialis keep you hard after coming what is better viagra or cialis