之前开发者计划优惠服务器99元每年,持续用了四五年了,目前优惠已过期,再续费太贵需要六七百
所以现在换了个服务器,也是阿里云的,刚好碰到活动,还是买了个99元的哈哈
够用就行~

数据已迁移完成,阿里云镜像快照真方便
迁移步骤:
1. 创建快照
2. 使用快照创建自定义镜像
3. 购买服务器
4. 停止新购买的服务器,然后选择更换操作系统,选择刚刚创建的自定义镜像,等待系统重启
5. 更换DNS域名解析、进入新服务器的宝塔后台,进行IP映射更换

分享技术,记录生活。
之前开发者计划优惠服务器99元每年,持续用了四五年了,目前优惠已过期,再续费太贵需要六七百
所以现在换了个服务器,也是阿里云的,刚好碰到活动,还是买了个99元的哈哈
够用就行~
数据已迁移完成,阿里云镜像快照真方便
迁移步骤:
1. 创建快照
2. 使用快照创建自定义镜像
3. 购买服务器
4. 停止新购买的服务器,然后选择更换操作系统,选择刚刚创建的自定义镜像,等待系统重启
5. 更换DNS域名解析、进入新服务器的宝塔后台,进行IP映射更换
docker 桌面版,默认安装在C盘且不让修改,但C盘又很容易满。
执行以下命令可修改
wsl -l -v
NAME STATE VERSION
docker-desktop Running 2
docker-desktop-data Running 2
wsl --export docker-desktop E:\docker\docker-desktop.tar
wsl --export docker-desktop-data E:\docker\docker-desktop-data.tar
wsl --shutdown
wsl --unregister docker-desktop
wsl --unregister docker-desktop-data
wsl --import docker-desktop E:\docker\docker-desktop E:\docker\docker-desktop.tar --version 2
wsl --import docker-desktop-data E:\docker\docker-desktop-data E:\docker\docker-desktop-data.tar --version 2我的新桌子

亮点:免安装,解压即可用,命令自动补全
WindTerm下载 https://github.com/kingToolbox/WindTerm/releases
WindTerm介绍文章:https://mp.weixin.qq.com/s/FFdpLhVmUfoarXM9xmshtw
写代码的时间都没有,这就是某公司的应届生入职集训。。。麻了
是这么个情况,宝塔上有个免费的SSL签名证书“Let's Encrypt”,用于https协议下,每三月自动免费续签一次,但最近我从日志发现续签失败了。手动试了下也失败,https已在项目域名中强制,所以如果无法续签,会影响项目的接口调用。
类似这样的错误(网图),重点 "验证URL无法被访问"
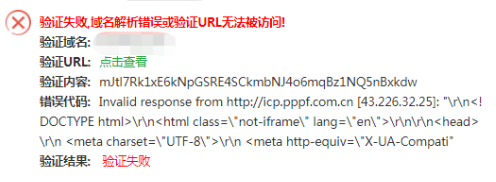
网上查了一圈,有好多方式都试了,但还是不行。
最后静下心来,想会不会是nginx没给放行,这也和上方的报错:无法被访问 说法相似,访问验证文件也是404

背景:某项目是前后端分离,也采用了安全的https和wss,这时候前后端分离下,采用Nginx处理跨域问题,自己会在配置文件中设置一些反向代理、放行的配置。
解决方案: 所以结合网上的参考,在nginx配置中加入以下规则配置,再手动续签一次就行了,后续自动续签也是成功了,总结原因:其实就是因为项目用了Nginx,导致签名验证文件访问不到,所以续签失败了,只要加放行规则,让那文件能正常被访问就OK啦
location ~ .well-known{
root /www/wwwroot/reservation.cstweb.top;
allow all;
}
突发奇想,说干就干,想做个用户可以分享自定义的抽奖事项、邀约朋友快速参与抽奖的小项目,就当练练手和巩固技术。
我期望:轻量级、好拓展、页面简洁美观、趣味性且开源的抽奖类项目。
大致需求:
主要涉及技术:
Spring Boot、Vue 、Element UI 、MySQL、MyBatis Plus、Redis、RabbitMQ、Websocket、并发场景处理、对接GoGo支付、开源抽奖概率算法、开源抽奖UI组件Lucky-Canvas(https://100px.net/demo/more.html)
项目开源地址(开发中):
后端:https://gitee.com/gitcst/luck-service
前端:https://gitee.com/gitcst/luck-front
最终项目网址:https://luck.cstweb.top (初版已上线)
备注:此项目含有概率性的性质,国家政策原因,无法接入真实支付场景,本项目仅用于练手、无盈利想法。
我们开发的项目,如果想做真实支付(非沙箱),可直接对接微信或支付宝等,但需要提供营业执照等信息,显然不现实且麻烦,所以用其它支付平台作为代理的角色来实现是个不错的方式,支付功能已在个人毕设项目实践。效果挺好,推荐下第三方在线支付对接平台:GoGo支付 (目前此平台已倒闭失效,仅供参考。)
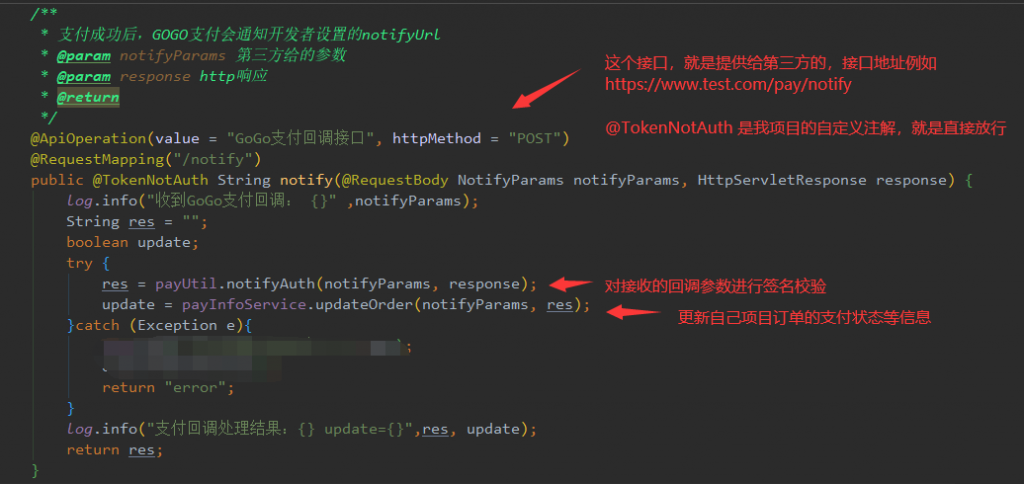
大致流程:后端项目中写个支付处理工具类 -> 调用支付请求 -> 等待和GOGO监控用户支付状态 -> 后端接收支付回调(需提供回调接口) -> 处理支付后业务逻辑 -> 跳转至成功页
效果一览
1.个人项目的支付面板

2.选择金额后,调用第三方支付接口,跳转至待支付页面。
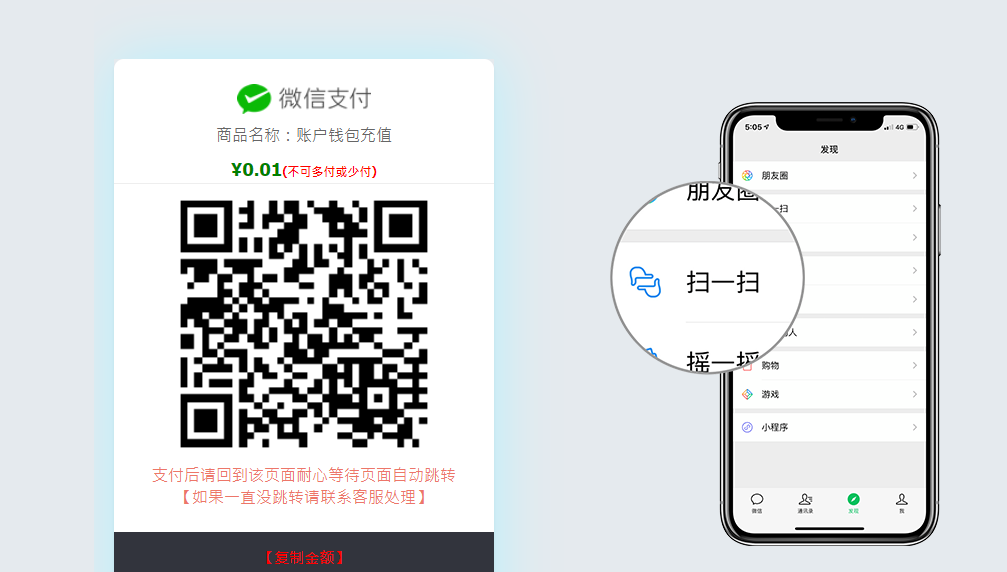
3.打开手机微信扫一扫,进行支付(第三方会做监听,但我们需要提供回调接口来实时获取 支付状态)

4. 支付成功,在回调接口中处理自己项目中的业务逻辑,然后3秒内页面会自动跳转至成功页(页面可自己指定)
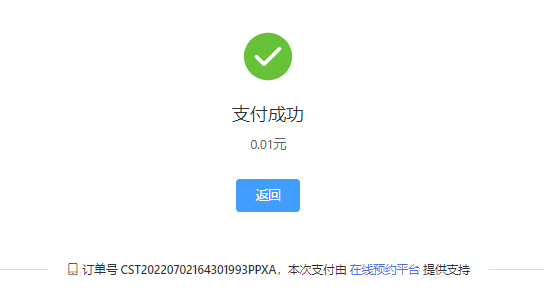
流程大致就这样啦,还有这种对接接口,一般都需要秘钥ID和Key,这个第三方会提供,作用就是标识身份。
下面来看看代码(只贴些核心对接代码)
1.给项目前端提供的支付接口
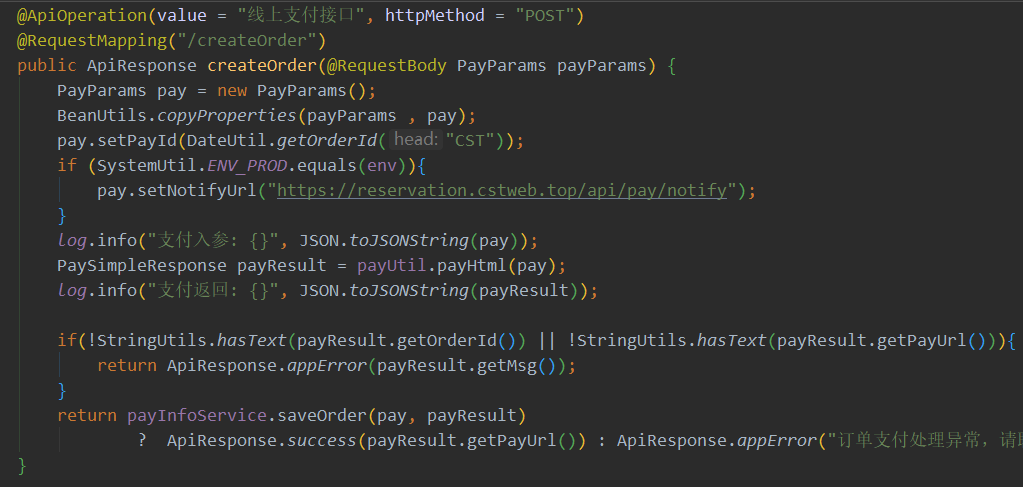
2.项目后端中直接http 发起POST请求 第三方支付接口
String paramsString = JSONObject.toJSONString(payParams);
String result = HttpUtils.goPost(CREATE_ORDER_URL, param
sString);
// 例子1,可直接用跳转方式,也可以用String字符串截取支付链接的方式,自由控制 <script>window.location.href = 'https://v14.gogozhifu.com/shop/go/pay.html?orderId=2022050114461185529786'</script>
log.info("上方是支付返回参数:{}", result);3.回调接口代码
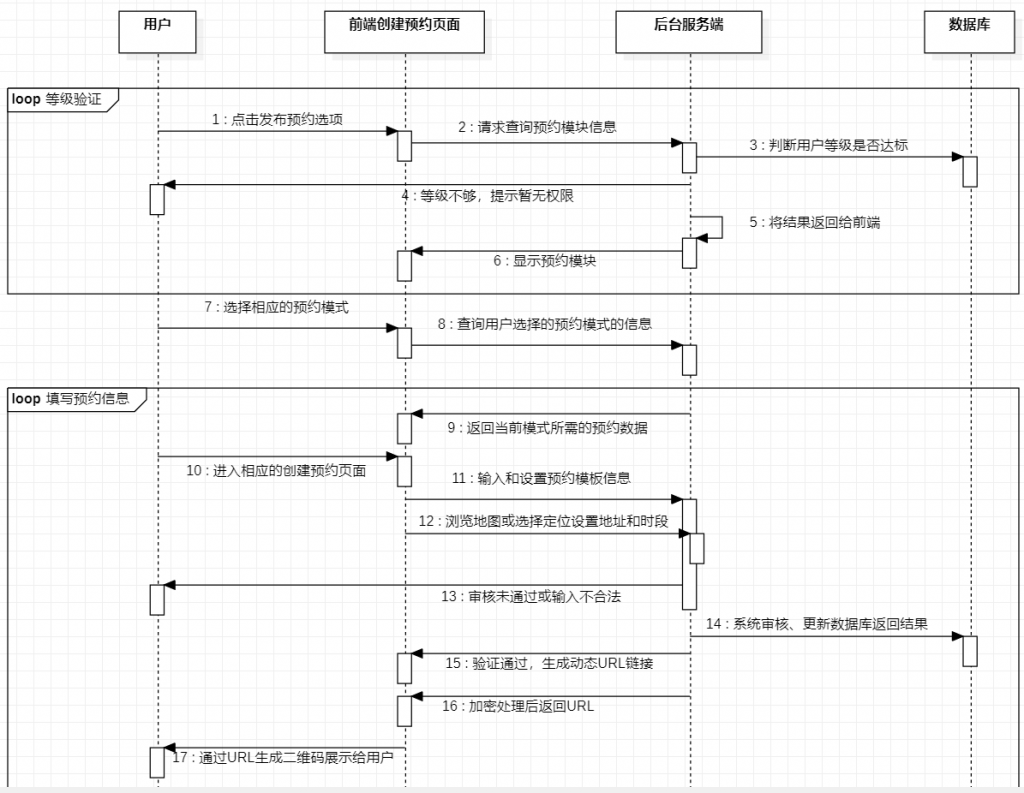
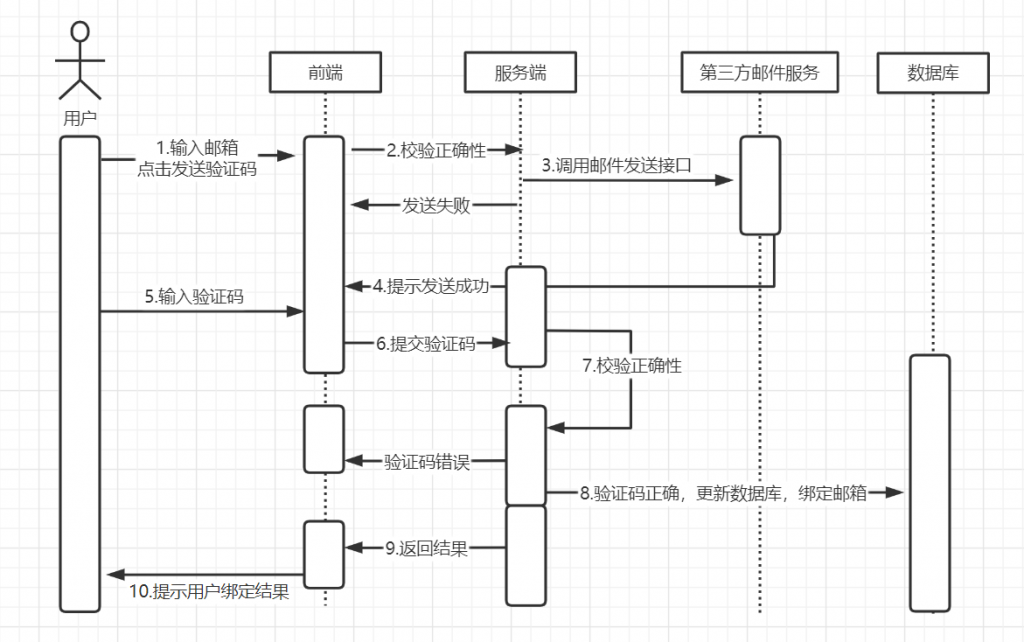
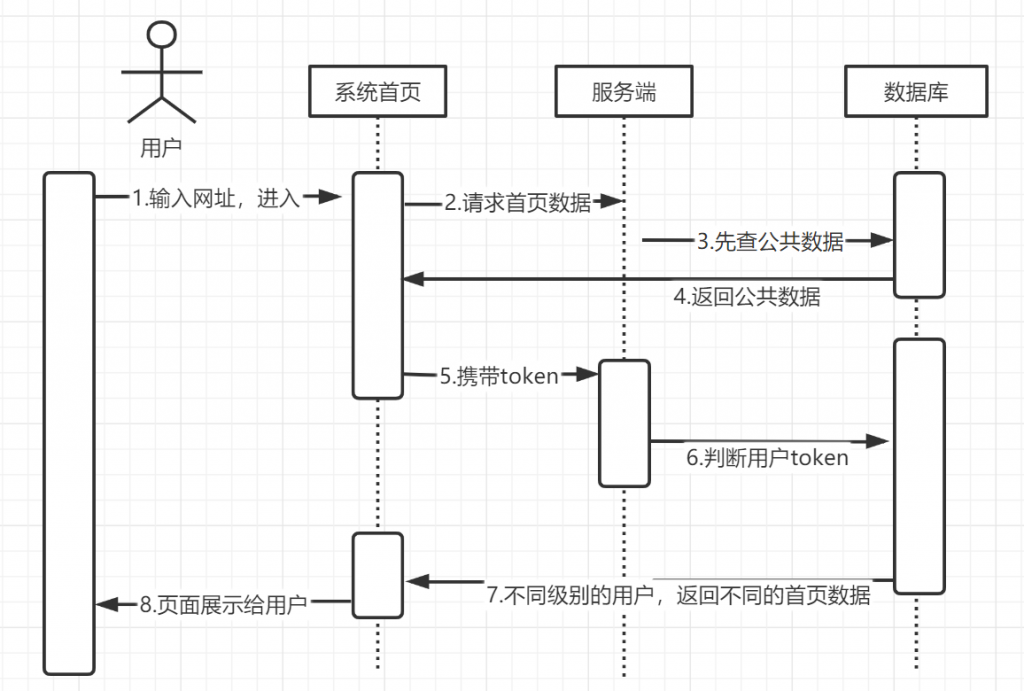
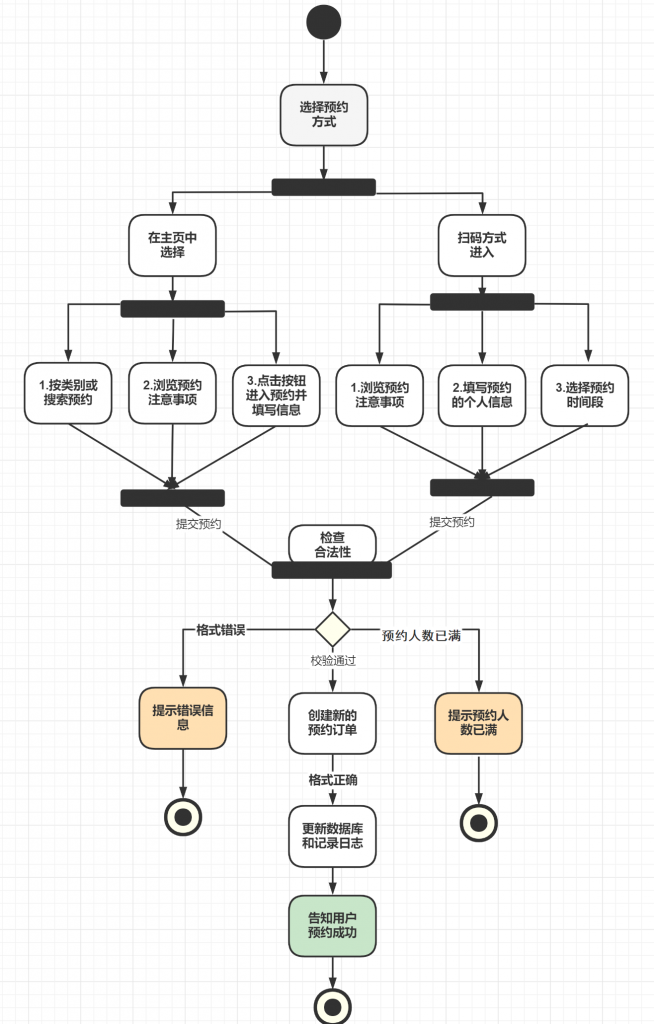
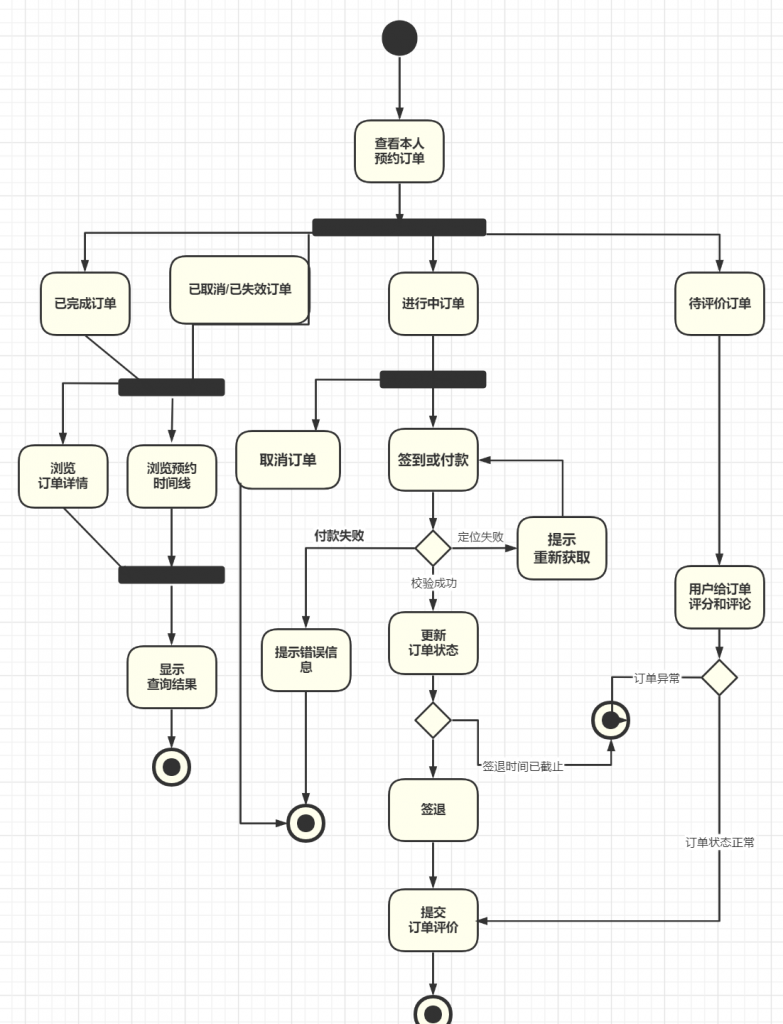
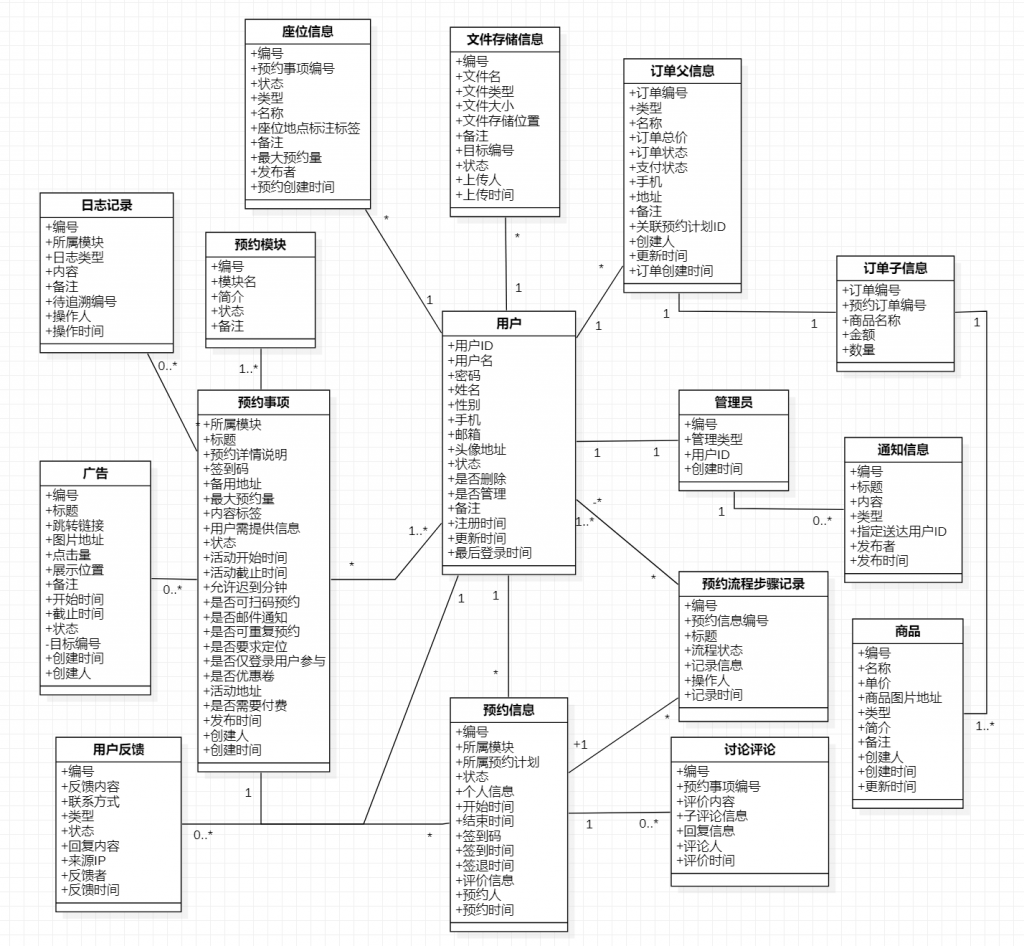
大学四年真的好快呀,我的毕设和论文搞了2个月左右,搞完啦~
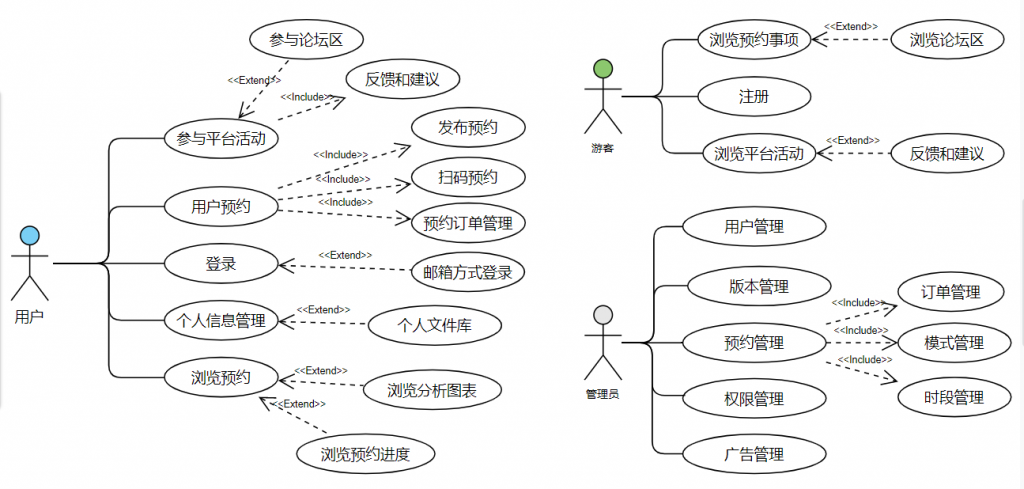
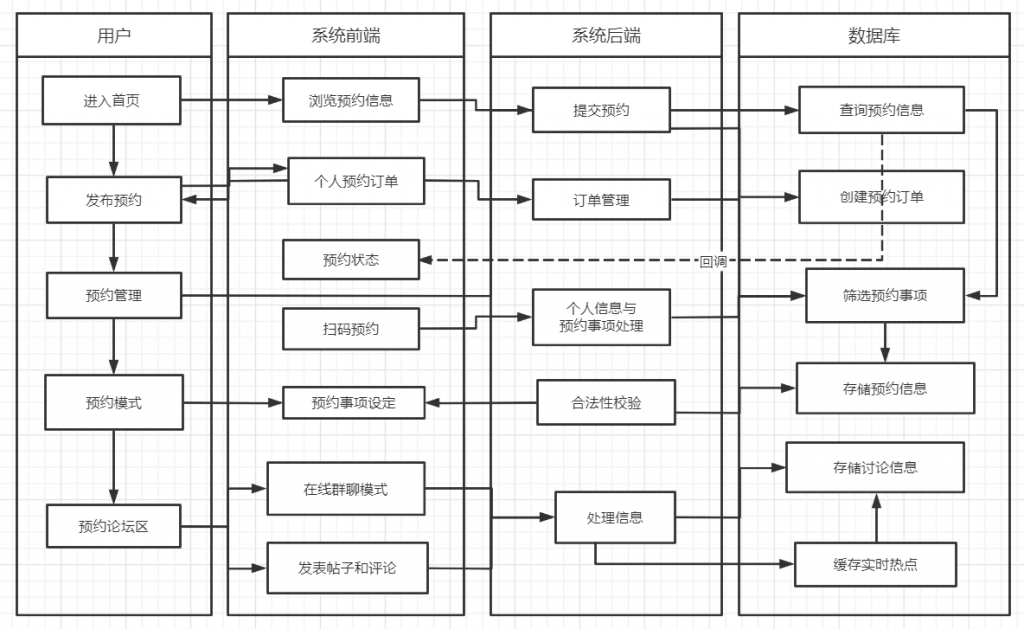
我做的是 预约类项目。
话不多说,上网址,点击下方链接去体验!
https://reservation.cstweb.top
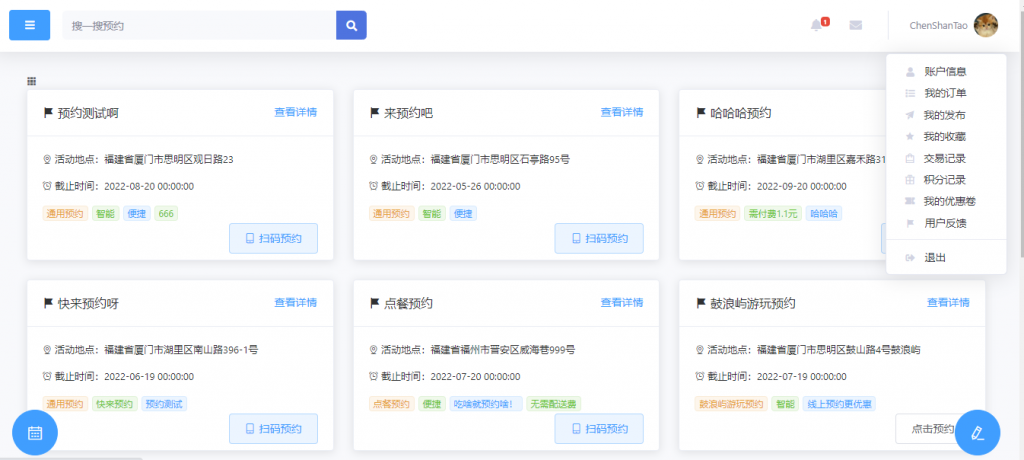
也可以先来看几张项目效果图吧!
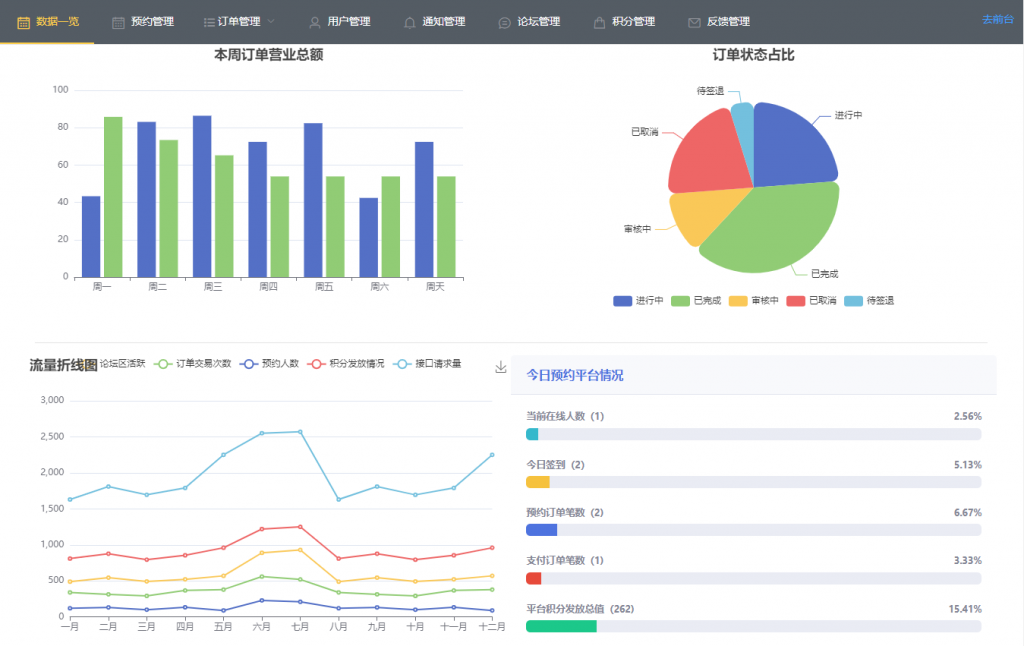
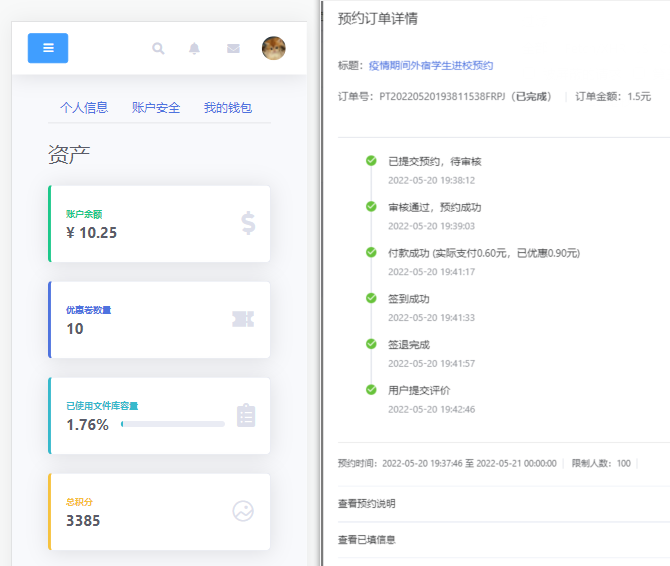
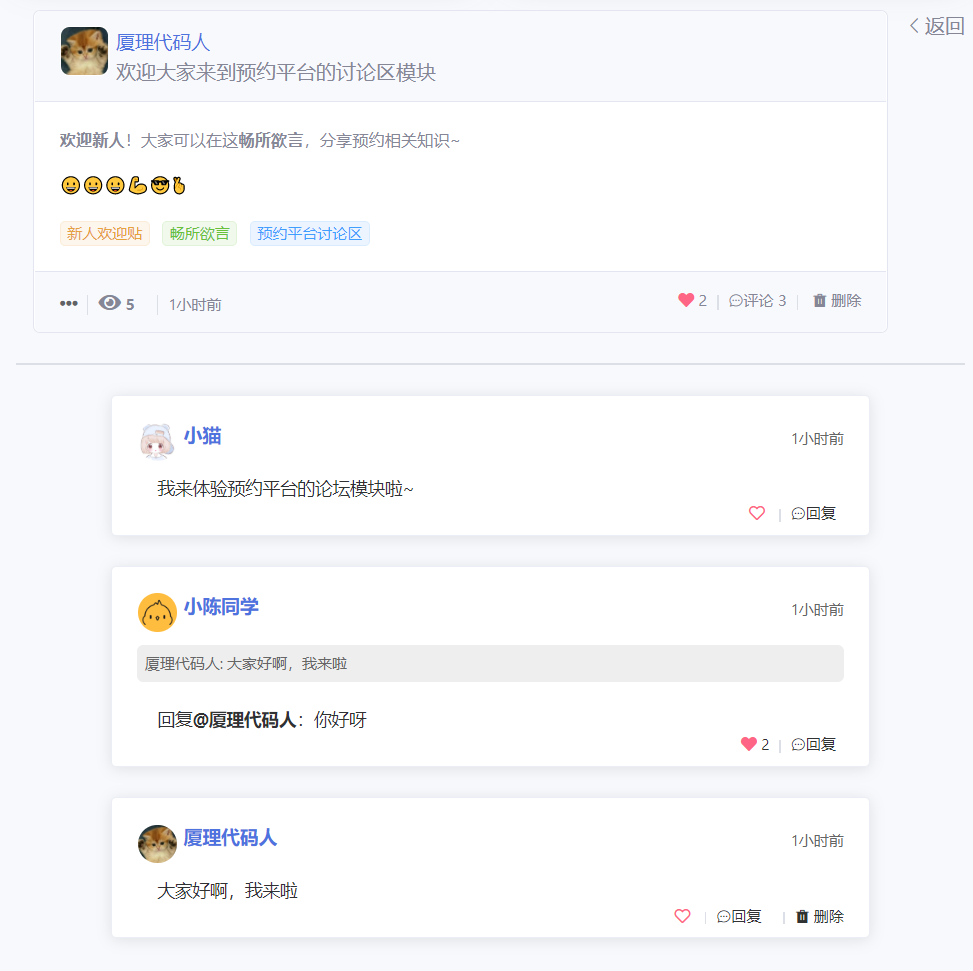
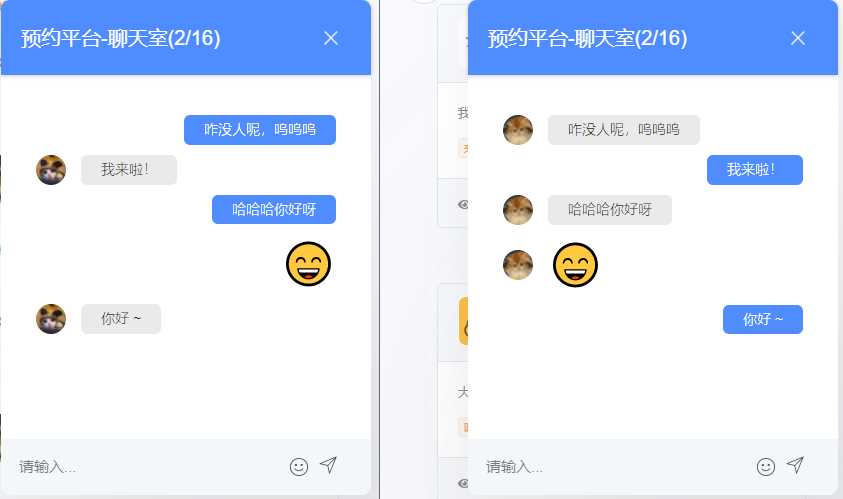
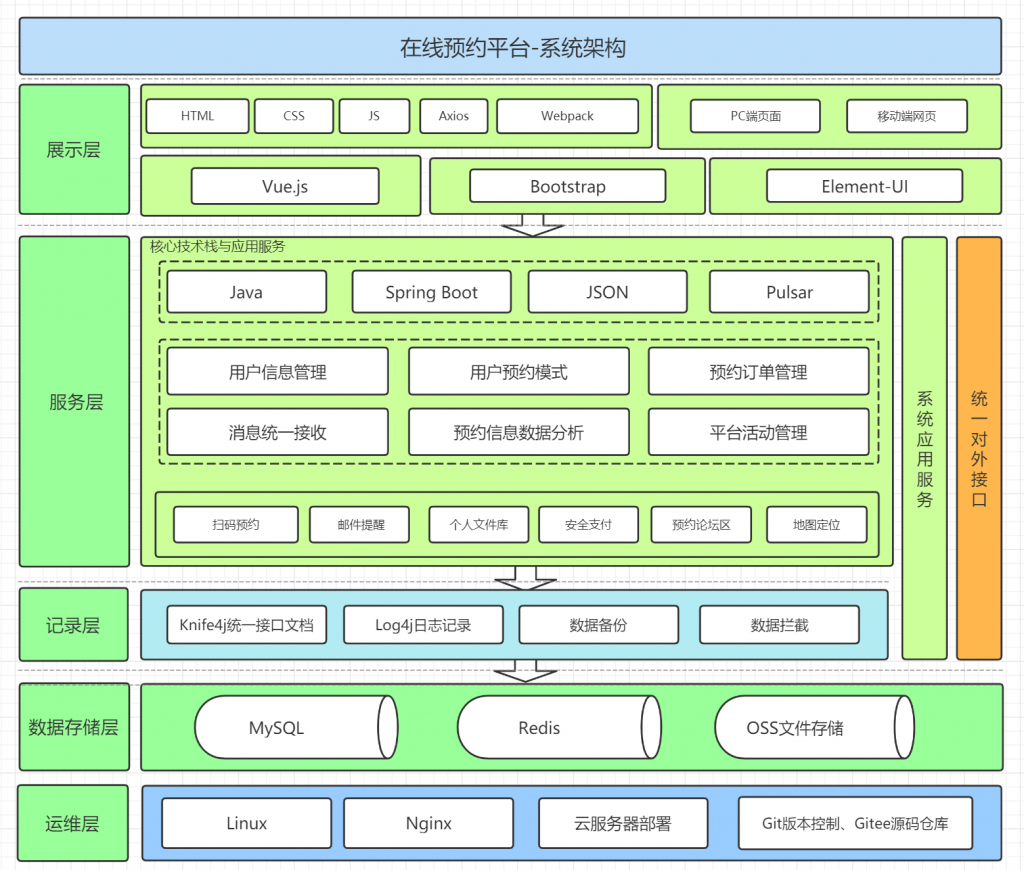
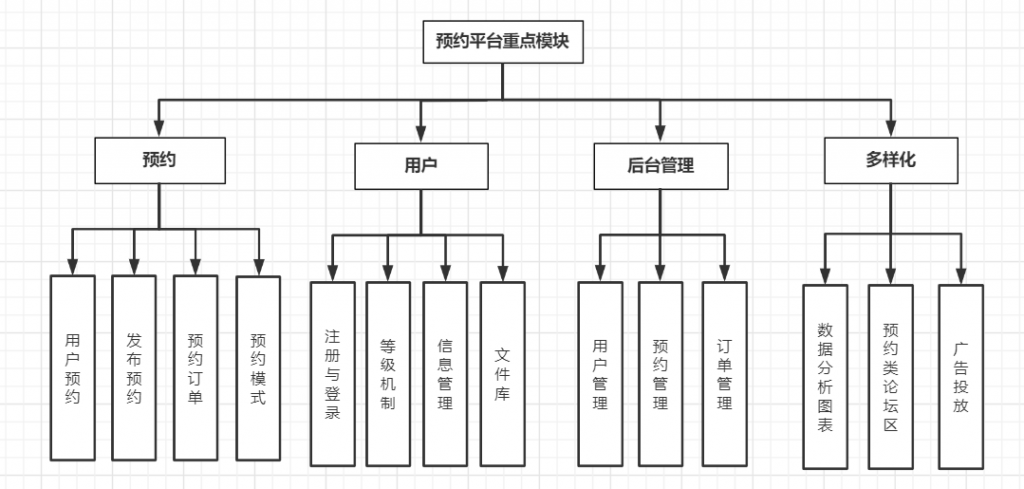
主要涉及技术

项目亮点

系统架构图
备注:这个项目还有蛮多可以完善和优化的地方,我后续会继续更新维护!

后端源码: https://gitee.com/gitcst/reservation-service
前端源码:https://gitee.com/gitcst/reservation-front
目前为私仓,整理审核后开源